Large Language Models (LLMs) are revolutionizing the world. According to the scaling laws [Kaplan et al, 2020] and additional evidence, bigger model sizes yield better-performing models. However, their financial and computational demands are significant. This study aims to reduce the inference costs of LLMs through structured pruning, which is effective in achieving hardware-independent speedups.
🍀 Resources for more information: GitHub, ArXiv.
🍀 Accepted at ICLR’24 Workshop on ME-FoMo and featured on Daily Papers by AK.
An LLM is a stack of multiple Transformer blocks [Vaswani et al., 2017], each of which contains a multi-head attention (MHA) module and a feedforward network module (FFN). In terms of structured pruning over LLMs, width pruning has initially been attempted. LLM-Pruner [Ma et al., 2023] and FLAP [An et al., 2024] reduce the network width by pruning attention heads of MHA modules and intermediate neurons of FFN modules. In this work, we propose a depth pruning method for LLMs by removing some Transformer blocks. We perform a comparative analysis between two pruning dimensions, network width vs. depth, regarding their impact on the inference efficiency of LLMs, as shown in Figure 1.
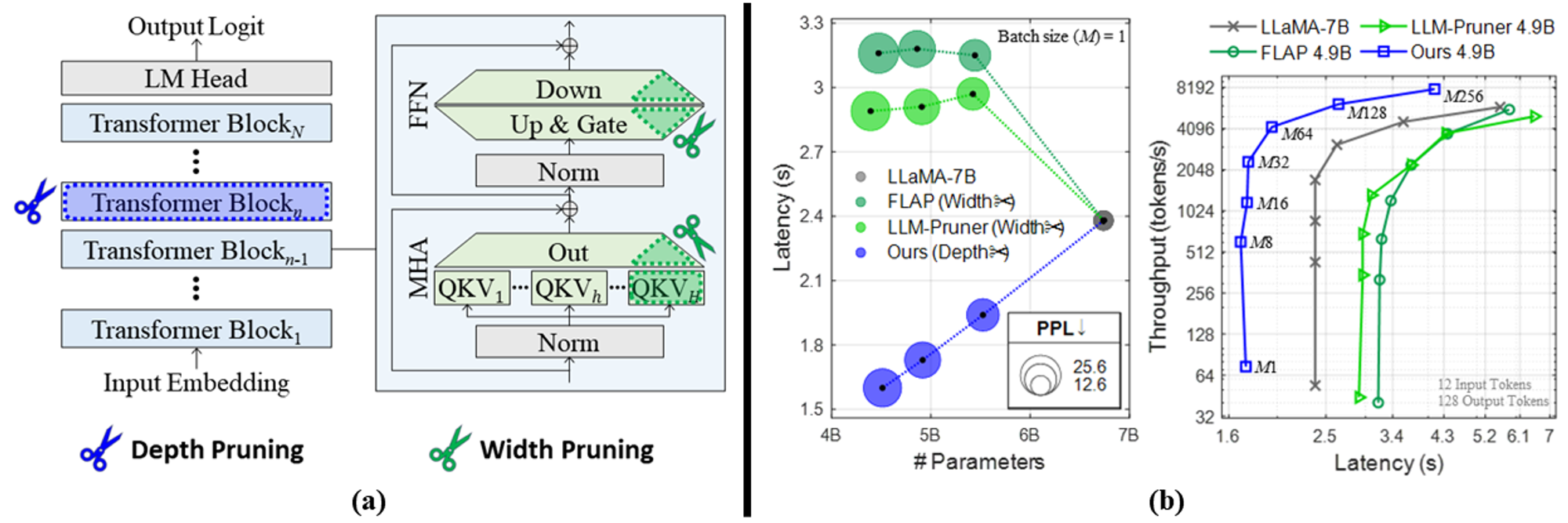
Figure 2 shows our approach. We begin by calculating the importance of each block to identify which blocks should be removed. Then, we perform one-shot pruning by removing several blocks simultaneously. Once the pruned network is obtained, we apply LoRA retraining [Hu et al., 2022] to recover the generation performance in a fast and memory-efficient manner.
![Figure 2. Our depth pruning approach. After identifying unimportant blocks with straightforward metrics, we perform one-shot pruning followed by light retraining. Right LoRA figure was sourced from Hu et al. [2022] .](https://cdn.prod.website-files.com/69d764b1be3398a43fb536b5/6a0414135924d32fefe8f19a_69e09b0b32dc64a1b9d1e9b6_img-a1917b3cb98f.webp)
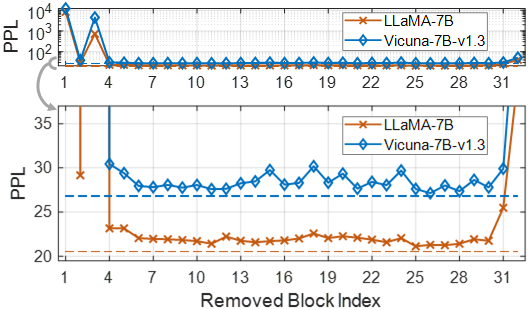
Our focus is on accelerating LLM inference under small-batch conditions caused by hardware restrictions. Such situations are relevant for deploying LLMs on memory-limited local devices. Figure 4 shows quantitative results, and Figure 5 presents qualitative generation examples.
Reducing weight sizes via width pruning is ineffective in speeding up generation, because of the memory-bound nature of LLM inference. Additionally, width pruning can even degrade the speed when the resulting weight sizes are unsuitable for GPU capabilities.
Our method achieves inference speedups while obtaining similar zero-shot performance compared to width pruning methods. We demonstrate that notable speed gains can only be achieved using depth pruning, which entirely removes some modules.
![Figure 4. Results of pruned LLaMA-1-7B [ Touvron et al., 2023 ] and Vicuna-v1.3-13B [ Chiang et al., 2023 ]. The width pruning methods of Wanda-sp [ Sun et al., 2024 ; An et al., 2024 ], FLAP [ An et al., 2024 ], and LLM-Pruner [ Ma et al., 2023 ] often degrade inference efficiency. In contrast, our depth pruning approach enhances generation speed and competes well in zero-shot task performance.](https://cdn.prod.website-files.com/69d764b1be3398a43fb536b5/6a0414135924d32fefe8f1a4_69e09b0e576a2b0919deb1fd_img-73c76cf67dec.webp)

We compress LLMs through the one-shot removal of several Transformer blocks. Despite its simplicity, our depth pruning method (i) matches the zero-shot performance of recent width pruning methods and (ii) improves inference speeds in small-batch scenarios for running LLMs.