
대형 언어 모델(LLM)은 세계에 혁신을 가져오고 있습니다. [Kaplan et al, 2020]의 확장 법칙과 추가 증거에 따르면, 모델의 크기가 커질수록 모델의 성능이 더 우수해지는 것으로 알려져 있습니다. 그러나 이러한 모델은 상당한 재정적, 계산적 자원이 필요합니다. 이 연구에서는 구조적 가지치기 방식을 통해 대형 언어 모델의 추론 비용을 줄이고, 이를 통해 개별 하드웨어에서 모델의 처리 속도를 효과적으로 향상시키는 것을 목표로 하고 있습니다.
🍀 추가 정보를 위한 리소스는 여기서 확인하실 수 있습니다. : GitHub, ArXiv.
🍀 ICLR’24 Workshop on ME-FoMo에서 채택되었으며, Daily Papers by AK에 소개되었습니다.
대형 언어 모델은 여러 개의 트랜스포머 블록[Vaswani et al., 2017]이 쌓여서 구성되며, 각 블록은 다중 헤드 어텐션(MHA) 모듈과 순방향 신경망 (FFN)을 포함합니다. 대형 언어 모델에 대한 구조적 가지치기를 위해, 처음에는 너비 가지치기가 시도되었습니다. LLM-Pruner [Ma et al., 2023]와 FLAP [An et al., 2024]는 다중 헤드 어텐션 모듈의 어텐션 헤드와 순방향 신경망의 중간 뉴런을 가지치기하여 네트워크 너비를 줄입니다. 이번 연구에서는 트랜스포머 블록 일부를 제거하는 대형 언어 모델에 대한 깊이 가지치기 방법을 제안합니다. 저희는 대형 언어 모델의 추론 효율성에 미치는 영향을 비교 분석하며 너비와 깊이 두 가지 가지치기 차원을 비교했습니다 (그림 1 참조).
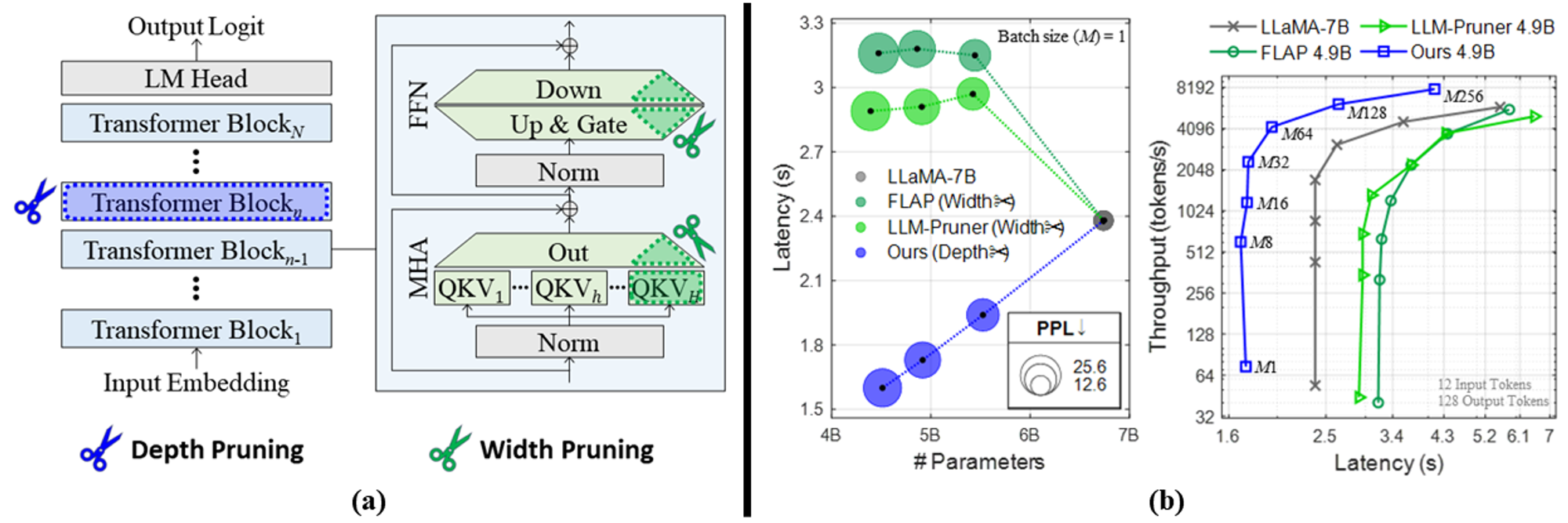
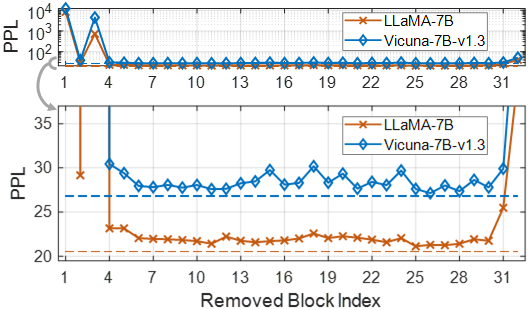
그림 2는 연구의 접근 방식을 보여줍니다. 먼저, 각 블록의 중요도를 계산해 제거해야 할 블록을 식별합니다. 이후 여러 블록을 한 번에 제거하는 일회성 가지치기를 수행합니다. 가지치기된 네트워크를 얻은 후에는 빠르고 메모리 효율적인 방식으로 생성 성능을 회복하기 위해 Low-Rank Adaptation (LoRA) 재훈련 [Hu et al., 2022]을 진행합니다.
![그림 2. 저희의 깊이 가지치기 접근 방식입니다. 간단한 지표를 사용해 중요하지 않은 블록을 식별한 후, 일회성 가지치기를 수행하고 간단한 재훈련을 진행합니다. 오른쪽에 있는 LoRA 그림은 Hu et al. [2022] 에서 인용한 것입니다.](https://cdn.prod.website-files.com/69d764b1be3398a43fb536b5/6a0414135924d32fefe8f19a_69e09b0b32dc64a1b9d1e9b6_img-a1917b3cb98f.webp)
저희는 하드웨어 제약이 있는 소규모 배치 환경에서 대형 언어 모델의 추론 속도를 향상시키는 데 중점을 두었습니다. 이는 메모리가 제한된 로컬 장치에 대형 언어 모델을 배포할 때 자주 발생하는 상황입니다. 그림 4는 정량적 결과를, 그림 5는 정성적 생성 예시를 보여줍니다.
너비 가지치기를 통해 가중치 크기를 줄이는 것은 대형 언어 모델의 추론 속도 향상에 효과적이지 않습니다. 이는 대형 언어 모델의 추론이 메모리 제한에 크게 영향을 받기 때문입니다. 또한, 너비 가지치기는 가지치기 후의 가중치 크기가 GPU 성능에 맞지 않을 경우 오히려 속도를 저하시킬 수 있습니다.
저희 방법은 너비 가지치기 방법과 유사한 제로샷 성능을 유지하면서 추론 속도를 향상시킵니다. 특히, 일부 모듈을 완전히 제거하는 깊이 가지치기를 통해서만 눈에 띄는 속도 향상을 이룰 수 있음을 입증했습니다.
![그림 4. 가지치기된 LLaMA-1-7B [ Touvron et al., 2023 ]와 Vicuna-v1.3-13B [ Chiang et al., 2023 ]의 결과입니다. Wanda-sp [ Sun et al., 2024 ; An et al., 2024 ], FLAP [ An et al., 2024 ], LLM-Pruner [ Ma et al., 2023 ]의 너비 가지치기 방법은 추론 효율성을 저하시키는 경향이 있습니다. 반면 우리의 깊이 가지치기 접근 방식은 생성 속도를 향상시키고 제로샷 작업 성능에서도 우수한 경쟁력을 보입니다.](https://cdn.prod.website-files.com/69d764b1be3398a43fb536b5/6a0414135924d32fefe8f1a4_69e09b0e576a2b0919deb1fd_img-73c76cf67dec.webp)

저희는 여러 트랜스포머 블록을 한 번에 제거하여 대형 언어 모델을 압축했습니다. 단순한 방법임에도 불구하고 깊이 가지치기 방법은 (i) 최근의 너비 가지치기 방법과 유사한 제로샷 성능을 달성하며 (ii) 소규모 배치 환경에서 추론 속도를 향상시켰습니다.
이 연구에 대해 추가로 궁금한 점이 있으시면, 📧 contact@nota.ai로 문의해 주세요.
또한, AI 최적화 기술에 관심이 있으시면 🔗 netspresso.ai를 방문해 보세요.

.jpeg)