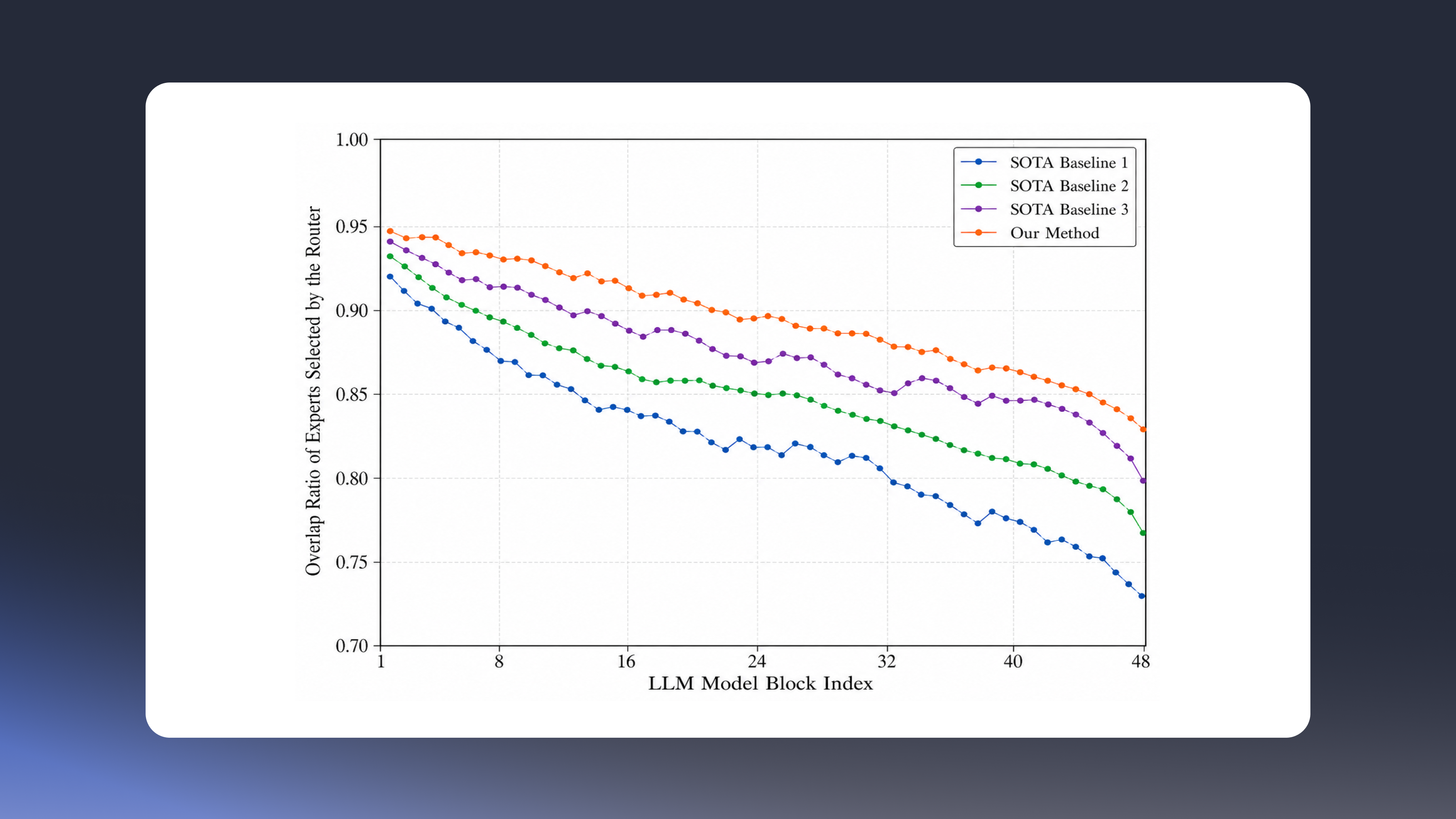
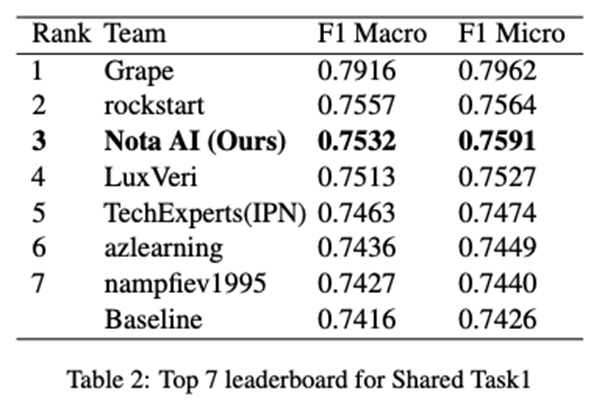
In this study, we explore methods for determining whether texts written in various languages were authored by humans or generated by LLMs. We have observed that classification accuracy significantly decreases for texts written in languages not observed during fine-tuning for the given task, even when using state-of-the-art multilingual pre-trained language models (PLMs). In other words, it appears that zero-shot cross-lingual transfer learning, where fine-tuning a multilingual PLM on a specific task in one language allows the model to perform the same task in other languages, does not work effectively. To address this issue, we propose a method that leverages two features to distinguish between LLM-generated texts and human-written texts, regardless of the language: token-level predictive distributions extracted from various LLMs and text embeddings from a multilingual PLM. With the proposed method, we achieved third place out of 25 teams in Subtask B of Shared Task 1, with an F1 Macro Score of 0.7532.
Recently proposed LLMs have demonstrated the ability to generate natural language with a level of fluency akin to that of humans, but they can still produce content that includes incorrect information. Due to this fluency, people may not realize that the generated text contains inaccuracies, making it easier for false information to spread as if it were true. This can lead to various negative consequences. As a result, detecting text generated by LLMs has become increasingly important. In particular, with numerous language models now supporting multilingual text generation, identifying LLM-generated text across different languages has also become a significant research topic.
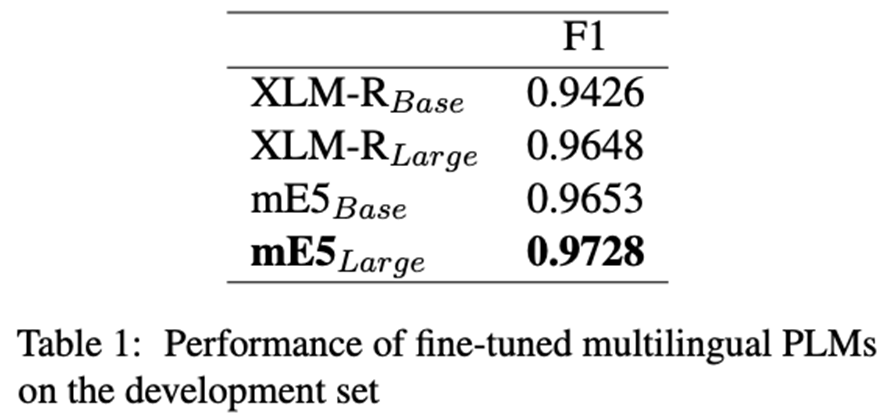
In our preliminary study, we observed that classification accuracy significantly decreases for texts written in languages not encountered during fine-tuning for the given task. To address this issue, our detection system for LLM-generated texts first identifies the language in which the given text is written. If the text is written in a language observed during the fine-tuning process, it is inferred using a model fine-tuned with supervised learning on a multilingual PLM. We fine-tuned various multilingual PLMs for our task and found that the multilingual e5-large model yields the best performance. Therefore, we use this model for seen languages (see Table 1).
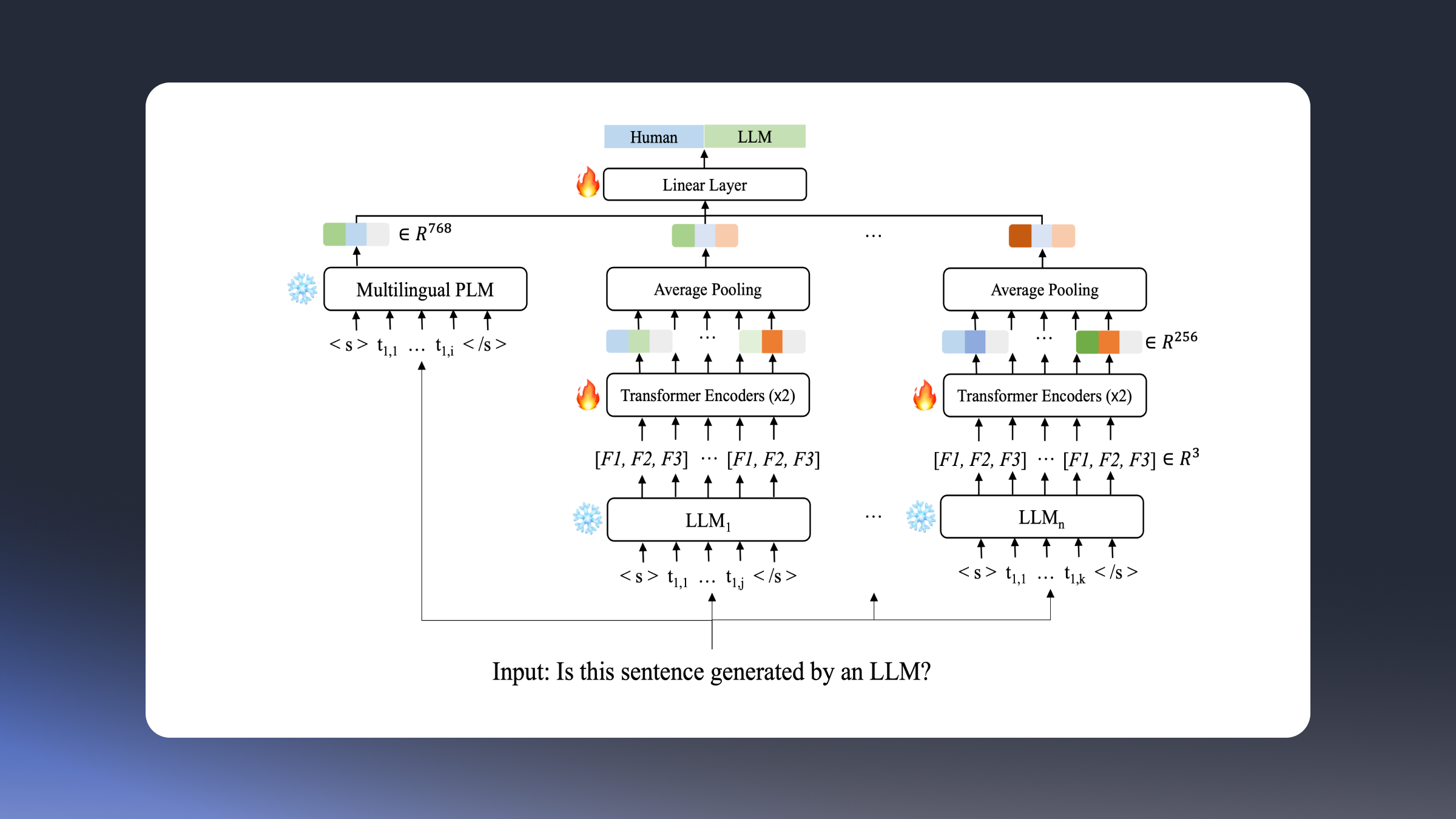
For texts written in unseen languages, they are inferred using a model that utilizes token-level predictive distributions extracted from various LLMs as features, along with a meaning representation from a multilingual PLM. LLMs are known to predict each token of LLM-generated texts with high probability values, while assigning relatively lower probabilities to each token of human-written texts, even for texts with the same meaning. Leveraging this characteristic, we extract the following three token-level predictive distributions from various LLMs for the given input text.
In this study, we extract these features from Llama-3.2-1B-Instruct, Qwen2.5-1.5B-Instruct, and Phi-3-mini-128k-instruct.
We also utilize the meaning representation extracted from a multilingual PLM. As a preliminary study, we translated 20 random English texts into all the languages used in the training and devtest sets provided for this shared task, and then extracted text embeddings from XLM-RoBERTa-base model. We considered the hidden state of the <s> token in the last layer as the text embedding, and visualized these embeddings in 2D using t-SNE. As a result, texts sharing similar meanings were positioned close to each other, regardless of the language, while texts with different meanings were positioned farther apart. Although this feature is language-agnostic and its relation to multilingual MGT is still uncertain, empirically, we observed that this feature improves the MGT detection performance. Before applying this feature, the F1 Score on the development set was 0.7114, but it improved significantly to 0.7370. As a result, our system utilizes this feature as well.
One plausible reason why the meaning representation could be useful is the following: LLMs often generate texts that deviate from common sense. Unless multilingual PLMs are intentionally trained to learn noise, these texts are likely to differ significantly from the commonsense knowledge learned by the PLMs. In other words, texts containing such incorrect information may be out-of-distribution samples and could be represented far from samples containing accurate knowledge in the embedding space. We will examine this hypothesis further in future work.
Based on the features described above, we train the model depicted in Figure 1. Since each language model has a different tokenizer, the given input is segmented into tokens of varying lengths, processed, and then combined to form a single feature vector. This feature vector is used for classification.
.png)
As described below, we achieved third place out of 25 teams in Subtask B (binary multilingual MGT detection) of Shared Task 1, with an F1 Macro Score of 0.7532.
In this study, we proposed a system for determining whether samples written in unseen languages are generated by LLMs. Our approach achieved third place in Subtask B of Shared Task 1. While we obtained a relatively high F1 Score compared to the baseline, it was not significantly higher. For future work, we should focus on investigating features that can better distinguish samples in unseen languages. Moreover, our approach relies on distinguishing between languages, which means that misidentifying the language type increases the likelihood of incorrect classification for that sample. Additionally, although we utilize smaller LLMs, extracting token-level predictive distributions incurs significant computational costs. In future work, we will also address these limitations.
If you have any further inquiries about this research, please feel free to reach out to us at following 📧 email address: contact@nota.ai.
Furthermore, if you have an interest in AI optimization technologies, you can visit our website at 🔗 netspresso.ai.