
기존의 자기 지도 시각 표현 학습(self-supervised visual representation learning) 기법들은 정적인 이미지에만 의존하며, 영상에 내재된 시간적 흐름이나 기하 구조와 같은 중요한 단서를 충분히 활용하지 못하는 한계가 있습니다. 본 논문에서는 학습 과정에 단 하나의 간단한 변화를 제안합니다. 바로, 현재 프레임의 임베딩을 기반으로 다음 프레임의 특성을 예측하도록 학생 네트워크를 훈련하고, 이를 지수 이동 평균(EMA) 방식으로 업데이트되는 방식입니다.
이 접근 방식은 객체 추적을 사용하는 DoRA나 광류를 사용하는 PooDLe처럼 복잡한 기법 없이도 더 뛰어난 성능을 보여줍니다. 구체적으로, 의미론적 분할(ADE20K)에서 36.4% mIoU, 객체 검출(COCO)에서 33.5 mAP를 기록하며 기존 최고 성능을 뛰어넘는 결과를 보여주었습니다.
이번 연구는 기존 자기 지도 학습 기법의 주요 한계 중 하나인 시간 정보 학습(temporal modeling)의 부재 문제를 해결합니다. 광류 추정기나 객체 추적기와 같은 고비용 모듈 없이도 간단한 보조 학습 목적 함수(auxiliary learning objective)만으로 인코더에 시공간적 추론 능력을 효과적으로 주입할 수 있습니다.
이 방식은 인코더의 아키텍처를 변경하지 않고도 표현력을 강화할 수 있어, 로보틱스나 임베디드 디바이스와 같은 환경에서도 손쉽게 적용할 수 있습니다. 또한, 학습 과정에서 사용되는 예측 헤드는 추론 단계에서 제거되므로 추론 효율성 역시 유지됩니다.
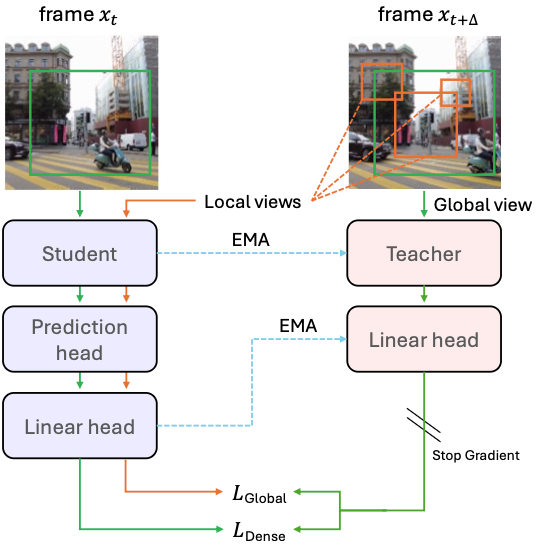
모델의 아키텍처는 DINO와 유사한 학생-교사 프레임워크를 기반으로 합니다. 학습 과정에서는 학생 네트워크가 현재 프레임(t)으로부터 다음 프레임(t+30)의 패치 단위 특징(patch-level features)을 예측하고, EMA 방식으로 업데이트되는 교사 네트워크가 그에 대한 타깃 특징을 제공합니다.
이를 통해 시간 정보를 반영한 밀집 특징 표현을 학습하면서도, 테스트 시에는 단일 프레임만으로도 효율적인 추론을 할 수 있습니다.
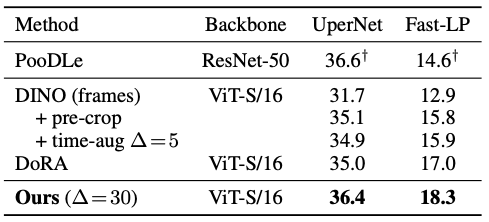
ADE20K 의미론적 분할에 대해서, UperNet 기반 파인튜닝(fine-tuning)과 선형 프로빙(linear probing, LP) 두 가지 설정에서 모델 성능을 측정하였습니다.
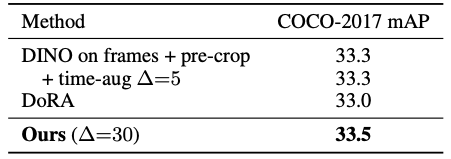
MS COCO 객체 검출 실험에서,
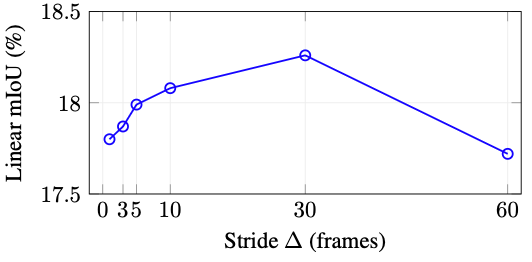
스트라이드(stride) 파라미터 Δ에 대한 추가(ablation) 실험 결과, 스트라이드 파라미터 Δ가 30일 때 가장 우수한 성능을 보였으며, 이는 너무 짧거나 긴 간격보다 적절한 시간적 맥락이 더 효과적이라는 것을 보여줍니다.
본 논문에서는 단일 이미지를 입력으로 받는 인코더가 ‘시간의 흐름’을 이해할 수 있도록 학습시키는, 단순하면서도 효과적인 자가 지도 학습 프레임워크를 제안합니다. Optical flow나 객체 추적과 같은 복잡한 기술 없이도, 다음 장면을 예측하는 훈련만으로 모델이 움직임이나 공간에 대한 지식을 스스로 학습할 수 있습니다.
이 방식은 이미지 속 객체를 의미 단위로 구분하는 의미론적 분할과 객체의 위치와 종류를 찾아내는 객체 검출에서도 좋은 성능을 보였습니다. 또한 로봇틱스나 비전-언어 시스템(vision-language systems)처럼 AI가 실제 물리적 환경에서 일어나는 상황을 이해하고 반응해야 하는 응용 분야에서도 실질적인 활용 가능성을 보여줍니다.
이 연구에 대해 추가로 궁금한 사항이 있으시면 아래 이메일 주소로 언제든지 문의해 주세요: 📧 contact@nota.ai.
또한, AI 최적화 기술에 관심이 있으시면 저희 웹사이트 🔗 netspresso.ai.를 방문해 보세요.

.jpeg)