Newsletter

🔹 The Challenges of MoE Quantization
🔹 The Algorithmic Axis: Nota MoE Quantization
🔹 The Data Axis: PASCAL-MoE
🔹 Where the Two Axes Meet
🔹 Looking Ahead — Where Nota AI Is Heading
.png)
The architecture beneath today's leading LLMs is changing. DeepSeek, GLM, Nemotron, and Solar — the latest generation of large language models has converged on Mixture-of-Experts (MoE). Unlike conventional dense models, where a single large network processes every token, an MoE model contains multiple expert sub-networks, and only a small subset of them is activated for each token. The promise is clear: a dramatic reduction in compute at inference time.
The reality is more complicated. While MoE addresses the compute problem, the memory problem remains intact. Even though only a few experts are active per token at inference, every expert must remain loaded in memory at all times — there is no way to know in advance which experts a given token will require. In practice, this means quantization is still essential for real-world deployment. The catch is that the quantization techniques carefully refined for the dense-model era do not transfer cleanly to MoE.
In this issue of Edge Insights, we focus on the two most pressing of these challenges — routing instability and calibration data bias — and examine how Nota AI is solving each, and what this means for the broader trajectory of LLM deployment.

Just last week, Nota AI took the Grand Prize at the NVIDIA Nemotron Hackathon, ranking first across all 20 competing teams. The winning entry was PASCAL-MoE, a synthetic data generation pipeline that addresses calibration data bias in MoE quantization head-on.
The win is significant in itself, but its full meaning becomes clearer when read alongside another recent milestone: Nota MoE Quantization (NMQ) — an algorithmic approach that integrates routing stability directly into the quantization loss function — adopted as the official quantization method for Solar-Open-100B, a flagship model of South Korea's Sovereign AI Foundation Model Project, a national initiative led by the Ministry of Science and ICT to develop independent foundation models for the country.
Read together, the two reveal Nota AI's research strategy: moving fast into the most pressing challenges in MoE quantization, from both algorithmic and data-centric directions.
MoE is rapidly establishing itself as the mainstream LLM architecture, but quantizing it efficiently is not a single problem — it is a tangle of distinct challenges, including router stability, biased activation statistics across experts, and the absence of low-bit kernels for sparse computation.
Where Nota AI has moved into first is the place that matters most in practice: the two challenges that show up first as performance degradation in real-world deployment — routing instability and calibration data bias.
Routing instability — the most frequently cited challenge.
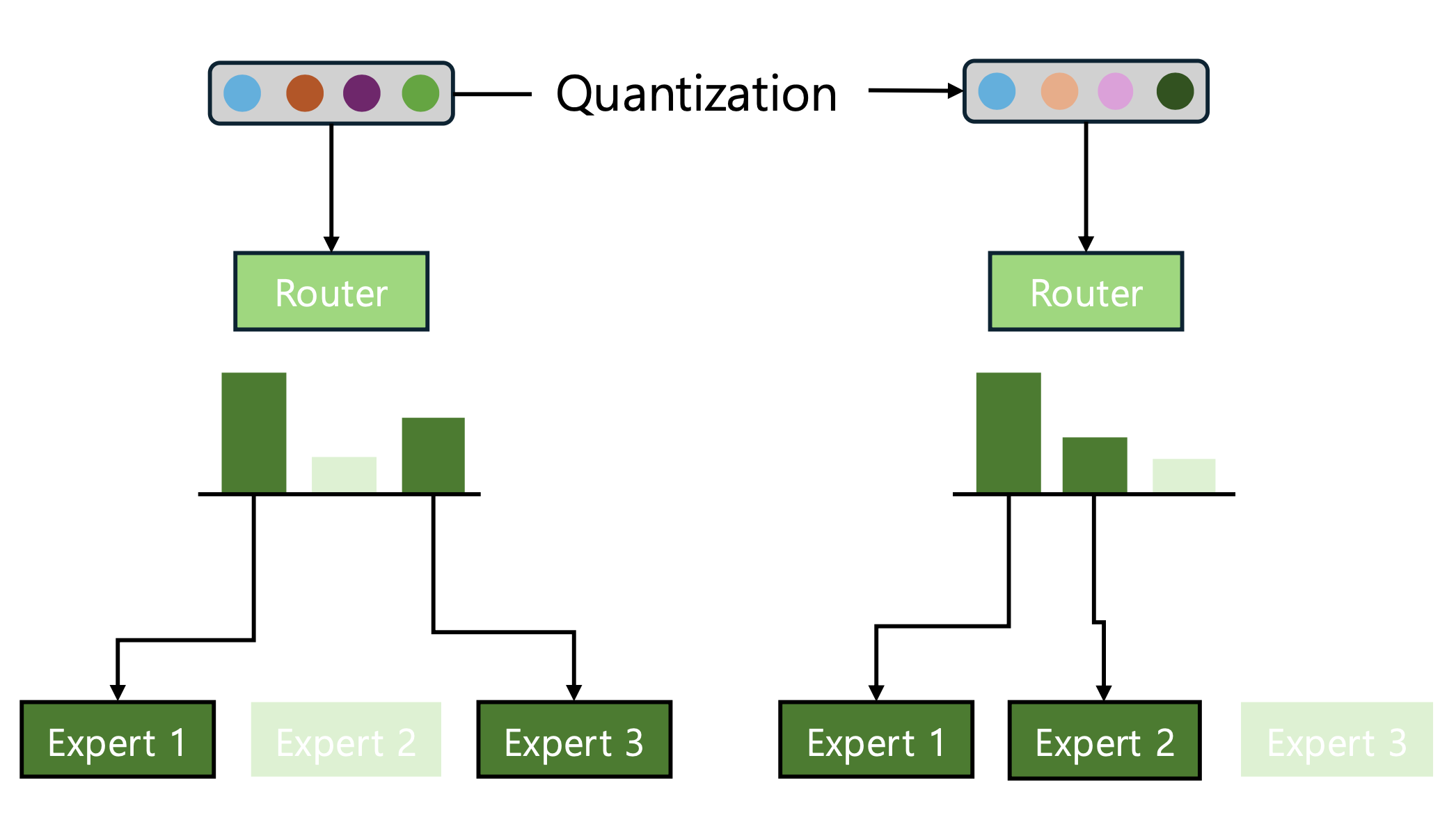
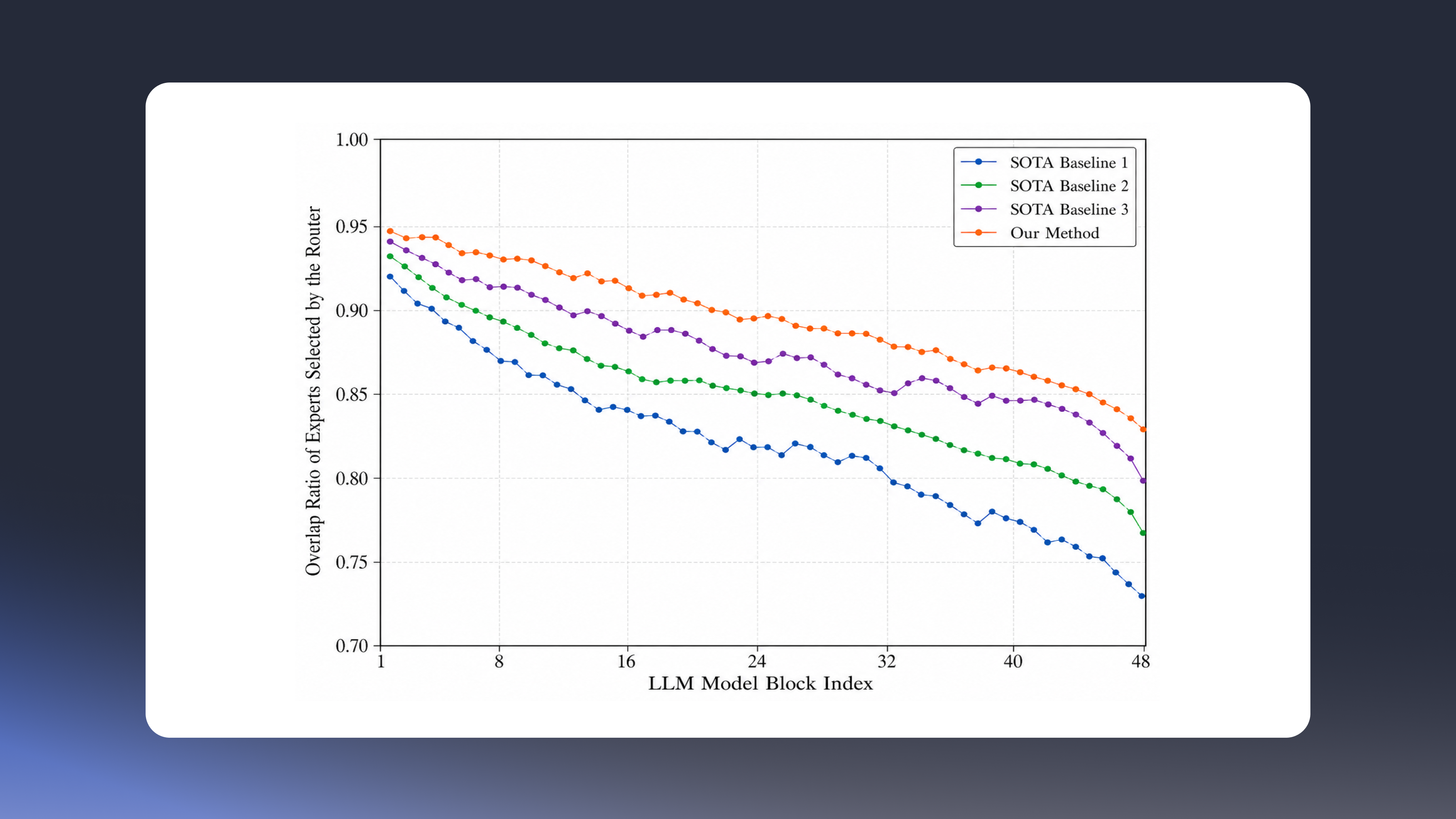
In a dense model, every token passes through the same network. When quantization shifts a value slightly, the consequence is a slightly less accurate output — graceful degradation. MoE works differently. Each token is routed to a small set of expert sub-networks, and the final output is a weighted combination of their results.
Quantization can perturb the router's logits enough to change which experts get selected. A token that should have gone to one set of experts is now processed by a different set entirely. The two groups produce outputs that are not interchangeable, and the result is not a small numerical drift but a sharp divergence in what the model returns.
Calibration bias — a less-discussed but rapidly emerging challenge.
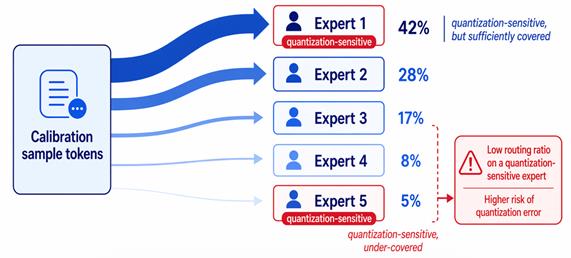
In the calibration data fed into the model just before quantization, MoE encounters another trap. Frequently activated experts and rarely activated ones develop a statistical gap, and if quantization-sensitive experts are not adequately covered, performance degradation accumulates. No matter how refined the algorithm is, if the data the algorithm sees is biased, the result will wobble.
The first response addresses routing instability at its source: the optimization process itself.
Conventional quantization methods compress every operation in a model uniformly. Fast and simple, but in an architecture like MoE — where routing decisions determine output quality — uniform compression can shift the very signals that govern those decisions, sending tokens to a different set of experts than the original model would have chosen.
NMQ takes a different approach. It focuses on preserving the router's decisions through quantization — keeping its logit values, the rank order among top experts, and the score margins between chosen and non-chosen experts close to the unquantized model. The goal is not adjusting precision layer by layer, but learning quantization parameters that protect the router's decision structure.
Concretely, NMQ introduces a Router Logits Alignment Loss — a function that protects the router's decision-making in two ways. First, it preserves the scores the router assigns to its top expert choices. Second, it preserves the relative ordering between those choices and the gap between the chosen experts and the just-missed candidates. Rather than treating routing stability as something to fix after the fact, NMQ integrates it into the quantization loss function from the start.
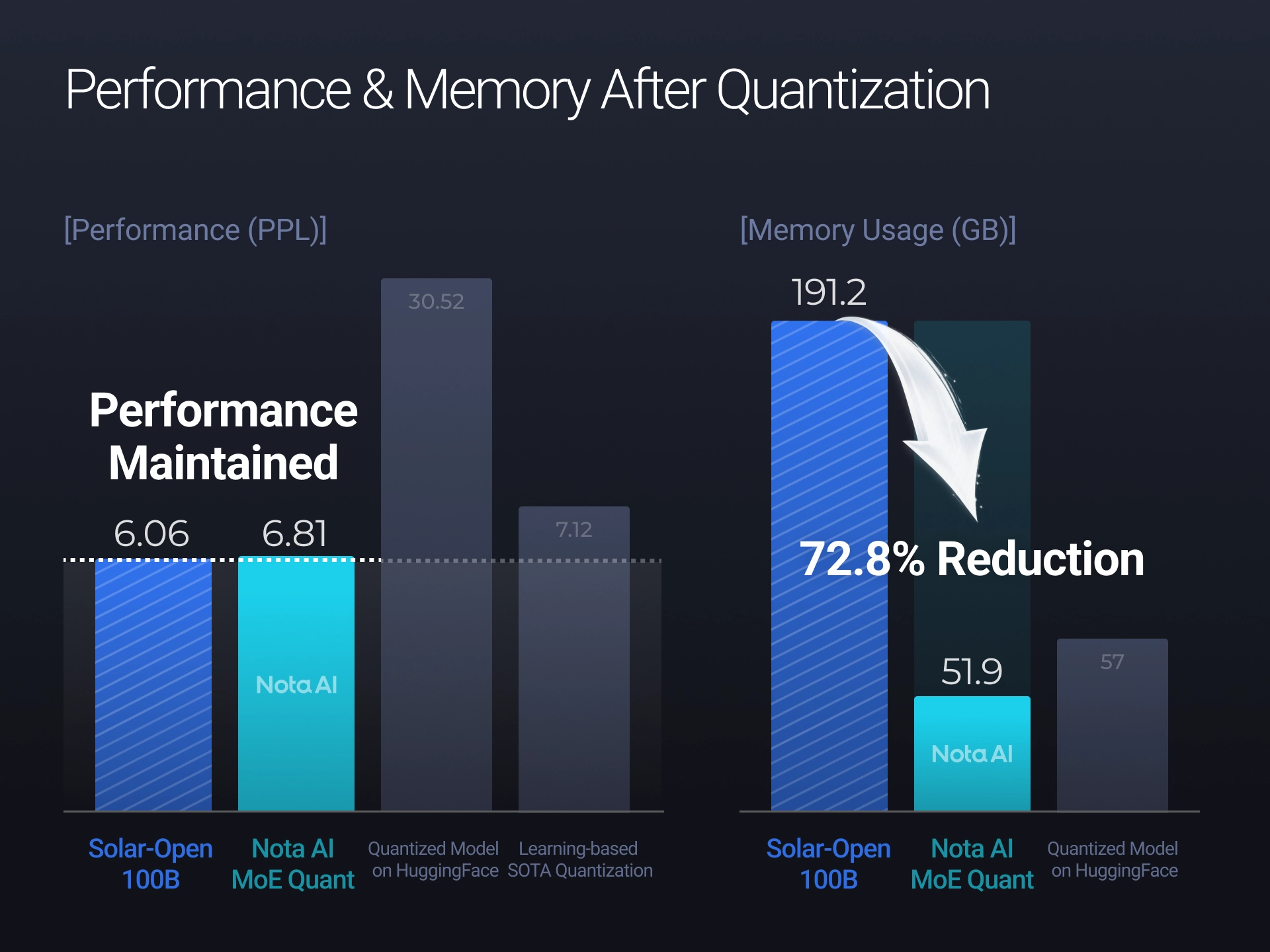
NMQ is built as a loss function, which means it can plug into existing quantization toolchains — AutoRound, GPTQ, and others — without changing the rest of the pipeline. The team applied it to Upstage's Solar-Open-100B, a 102-billion-parameter MoE model, and the results were substantial. Memory usage dropped from roughly 191GB to 52GB — about 73% smaller — while the model's quality stayed close to the uncompressed original (perplexity of 6.81 versus 6.06, where lower means better).
The contrast with general-purpose methods is sharp. Some standard quantization techniques have been observed to make MoE models more than five times worse on quality benchmarks; NMQ holds the line. On NVIDIA's latest B300 GPU, the gains compound at the speed layer as well: NMQ paired with NVFP4 (one of NVIDIA's newest low-precision formats) cuts response time roughly in half compared to the more conventional 4-bit setup — meaning users see the model's first reply almost twice as fast.
The model has been released on Hugging Face as the official quantized version of Solar-Open-100B.
👉 For a deeper technical look at NMQ, see the Nota AI Tech Blog — NotaMoEQuantization: An MoE-Specific Quantization Method for Solar-Open-100B
The second response addresses calibration data bias at a different point in the same pipeline — not the quantization algorithm itself, but the calibration data that goes into it.
Calibration datasets are short samples passed through the model to estimate which numerical ranges matter. For dense models, this is reasonably well-understood. For MoE, two forms of bias intrude.
Experts that are rarely activated by the calibration data receive sparse activation statistics, and their quantization parameters become unreliable. Quantization-sensitive experts compound the problem when not adequately covered.
PASCAL-MoE addresses both forms of bias. Using an agent built on NVIDIA's Nemotron-3-Super-120B, the pipeline analyzes which tokens activate under-utilized or sensitive experts, extracts the linguistic patterns that trigger them, and generates synthetic calibration samples designed to balance expert coverage.
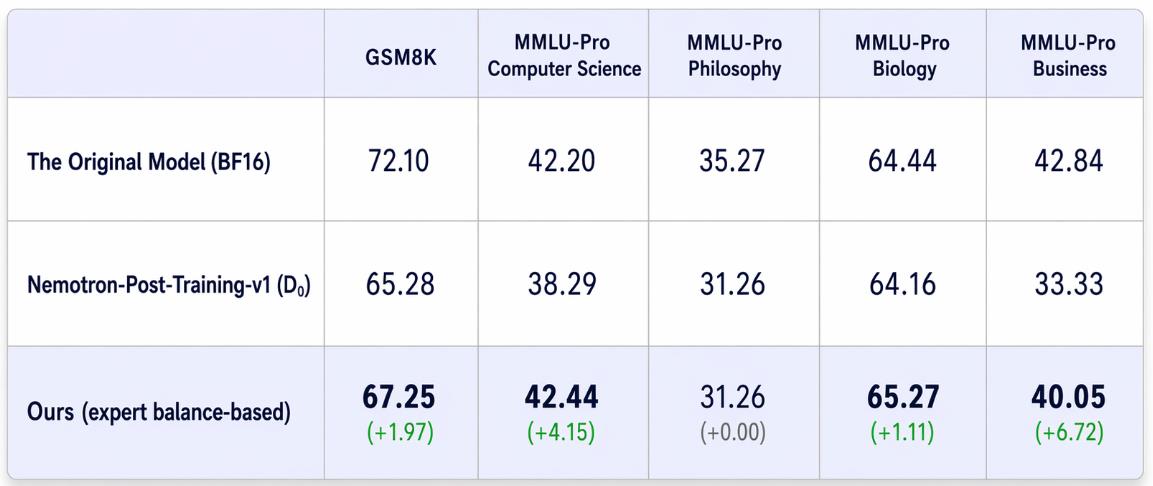
Where conventional quantization research has focused primarily on algorithmic and formula-driven optimization, PASCAL-MoE takes a different route — engineering the structure, quality, and task-alignment of the calibration dataset itself. It is a data-centric approach to one of the harder strands within the MoE quantization problem.
On Qwen3-30B-A3B with W4A16 quantization, the approach delivered consistent gains over standard calibration — including +1.97 on GSM8K, +4.15 on MMLU-Pro Computer Science, and +6.72 on MMLU-Pro Business. All of these gains came from changing the calibration data alone, with no change to the quantization algorithm itself.
The PASCAL-MoE pipeline currently treats expert balance and quantization sensitivity as independent objectives. Unifying them into a single coverage strategy is the next step. This is the work that earned Track C first place and the overall Grand Prize at the NVIDIA Nemotron Hackathon, evaluated against 19 other teams from across Korea's AI industry.
👉 For the behind-the-scenes story of those 48 hours — see the [NVIDIA Nemotron Hackathon] Grand Prize Among 20 Teams: Behind Two Sleepless Days
NMQ and PASCAL-MoE address two distinct challenges in MoE quantization at two different points in the same pipeline. Algorithm-centric quantization research remains the mainstream of the field — it is where the foundational mechanisms of quantization are designed and refined, and NMQ sits squarely within that tradition. Data-centric optimization operates at a different point in the same pipeline. The two are complementary directions.
As the center of gravity in AI optimization expands beyond "the compression algorithm itself" toward "how data is designed and leveraged," operating both axes together means moving into the two challenges that need to be untangled first in MoE quantization.
Combining the two axes is the natural next step. NMQ integration into NetsPresso® is already in progress, and PASCAL-MoE is on the same path pending additional validation. Once integrated, the two axes will operate as a single unified MoE optimization pipeline for NetsPresso® users — enabling the quantization and deployment of state-of-the-art MoE-based LLMs with minimal performance loss.
👉 Learn more about NetsPresso®: https://netspresso.ai/
The reason all of this work matters — moving from algorithm to data, and on toward kernels and hardware — comes down to a single question: who, and which problem, is this technology solving for? As the two axes are addressed together inside NetsPresso®, the result unfolds along two lines.
On one side, robots, vehicles, and edge devices — environments constrained by memory, power, and latency — gain a path to running state-of-the-art MoE-based LLMs without losing the capabilities that make them worth running.
On the other side, organizations that struggle to secure large-scale GPU infrastructure can serve more users without proportional infrastructure expansion: compressing memory footprint to roughly a quarter of its original size means more requests served on the same hardware, or the same service operated on less, which translates directly into operational cost reduction. Both lines reflect the same direction Nota AI has been building toward: AI optimization is no longer just about algorithmic refinement — it is about "building purpose-fit technology stacks that reach real industrial deployment."
As model architectures continue to evolve and specialize, the optimization techniques that worked for previous generations no longer suffice on their own. The companies that will matter in this next phase are the ones that move quickly into the challenges a shifting problem landscape brings. The era of training larger models has given way to the era of running them, and within that shift, MoE quantization still has multiple challenges left to solve. Nota AI is already moving toward what comes next — which is to say: on the path to making high-performance AI runnable wherever it needs to run, Nota AI is already a step ahead.

🔹 NVIDIA Nemotron Developer Days Seoul 2026 — Won Grand Prize with PASCAL-MoE, demonstrating a breakthrough in MoE quantization through synthetic data generation.
🔹 2026 Edge AI and Vision Product of the Year Award — NVA (Nota Vision Agent) recognized in the Edge AI Large Multimodal Models (LMM) category.

🔹 Embedded Vision Summit 2026 — May 11–13, Santa Clara · Booth #408