🔹 The Trillion-Dollar Inference Race Begins: How Nota AI Fills the Gap
🔹 This Month at Nota AI
🔹 Where to Meet Us Next
The AI industry has crossed a meaningful threshold. For years, competitive advantage meant training larger models — now the question has moved from what a model can do to how efficiently and reliably it can do it, across data centers, edge devices, and everything in between.
"The race to train models is over. The age of inference, that is, actually running those models, has arrived, and the competitive edge now lies in how deeply you can optimize that inference.”
At GTC 2026, NVIDIA CEO Jensen Huang made this transition explicit. His keynote reframed the AI infrastructure conversation around inference: the actual process of running models at scale. The implications extend well beyond server rooms — touching autonomous systems, industrial automation, robotics, and the growing ecosystem of AI-enabled devices operating under real-world constraints.
In this issue of Edge Insights, we examine what GTC 2026 revealed about the direction of the industry, and where Nota AI stands within it. We also highlight key milestones from March and share where you can meet the Nota AI team next.
NVIDIA's projected revenue opportunity for 2025–27 has doubled from 500 billion dollars to 1 trillion dollars. At the heart of this figure lies inference.
10,000x: The Anatomy of a Demand Surge
According to Jensen Huang, AI workload computation has grown 10,000-fold over the past two years. This is because the industry has moved beyond the chatbot era, where each request mapped one-to-one with a response, and entered the agent stage, where AI thinks, plans, and utilizes tools on its own. To handle a single task, an agent repeats cycles of reading, judging, calling tools, and verifying dozens of times. Token consumption is no longer linear. It's exponential.
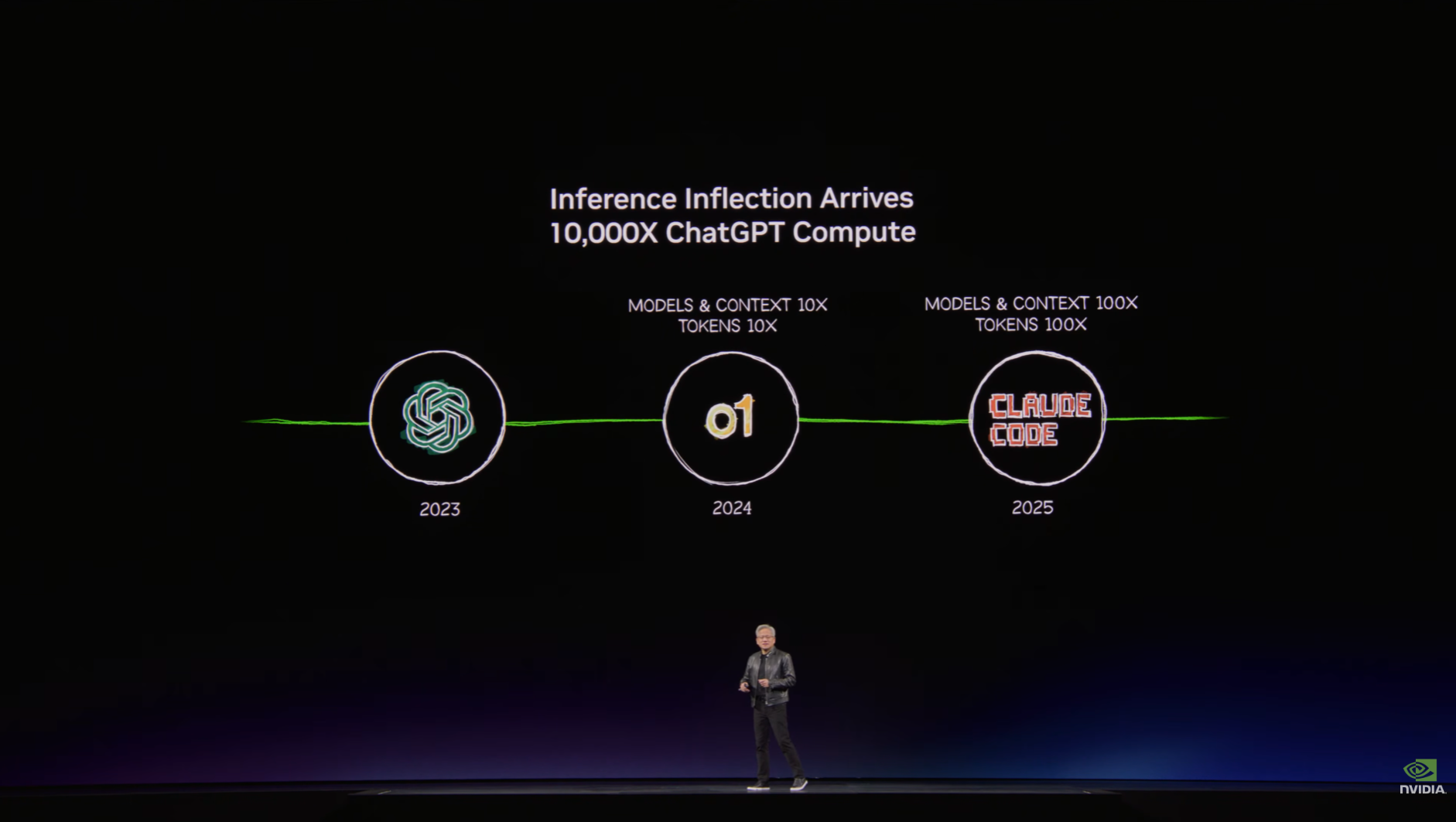
On top of this, as more enterprises and services adopt AI agents, overall demand is expanding rapidly. The result is a landscape where the organizations with infrastructure capable of generating more tokens at lower cost hold the advantage.
AI Factories: Redefining the Data Center
Data centers were once cost centers evaluated by server count, uptime, and storage capacity. Jensen Huang presented a different set of criteria this time. A data center's value is now determined by how many tokens it can produce per watt, how quickly and cheaply it can supply them, and whether it can handle longer contexts and more complex reasoning. The declaration is clear: data centers are transitioning from places that store data to AI Factories that produce tokens.
The metrics for measuring inference efficiency are shifting as well. While throughput (tokens processed per second) has been the primary measure until now, GTC 2026 put cost-based measures front and center: tokens per dollar and tokens per watt. The competitive edge no longer lies in how many tokens you can generate, but in how cheaply and quickly you can generate them.
OpenClaw, the product behind the Mac mini shortage, reached 2 million weekly users just two months after launch and was subsequently acquired by OpenAI. Manus surpassed 100 million dollars in ARR within eight months and was acquired by Meta for approximately 2 billion dollars. The movements of global big tech are converging on a single point: AI agents.
Building AI Agents Has Become Easy
What OpenClaw demonstrated was not just a product success. It showed that the era in which anyone can build their own agent has arrived, and that an agent's performance ultimately depends on how well it understands its user. Simply expanding the context window is not enough. It requires structuring and storing individual or organizational information so it can be retrieved at the right moment. This is why technologies like efficient long-context processing, KV cache management, and prefix caching for reusing repeated computations are becoming increasingly important.
Why AI Agents Need Guardrails
However, adopting agents remains far from straightforward for enterprises. Agents make decisions and take actions without human intervention. Freedom comes with responsibility, yet AI does not yet know how to bear it. In a system where a flawed judgment translates directly into action, unchecked freedom becomes negligence. This is precisely why guardrails are necessary — and it is the challenge NVIDIA chose to address.
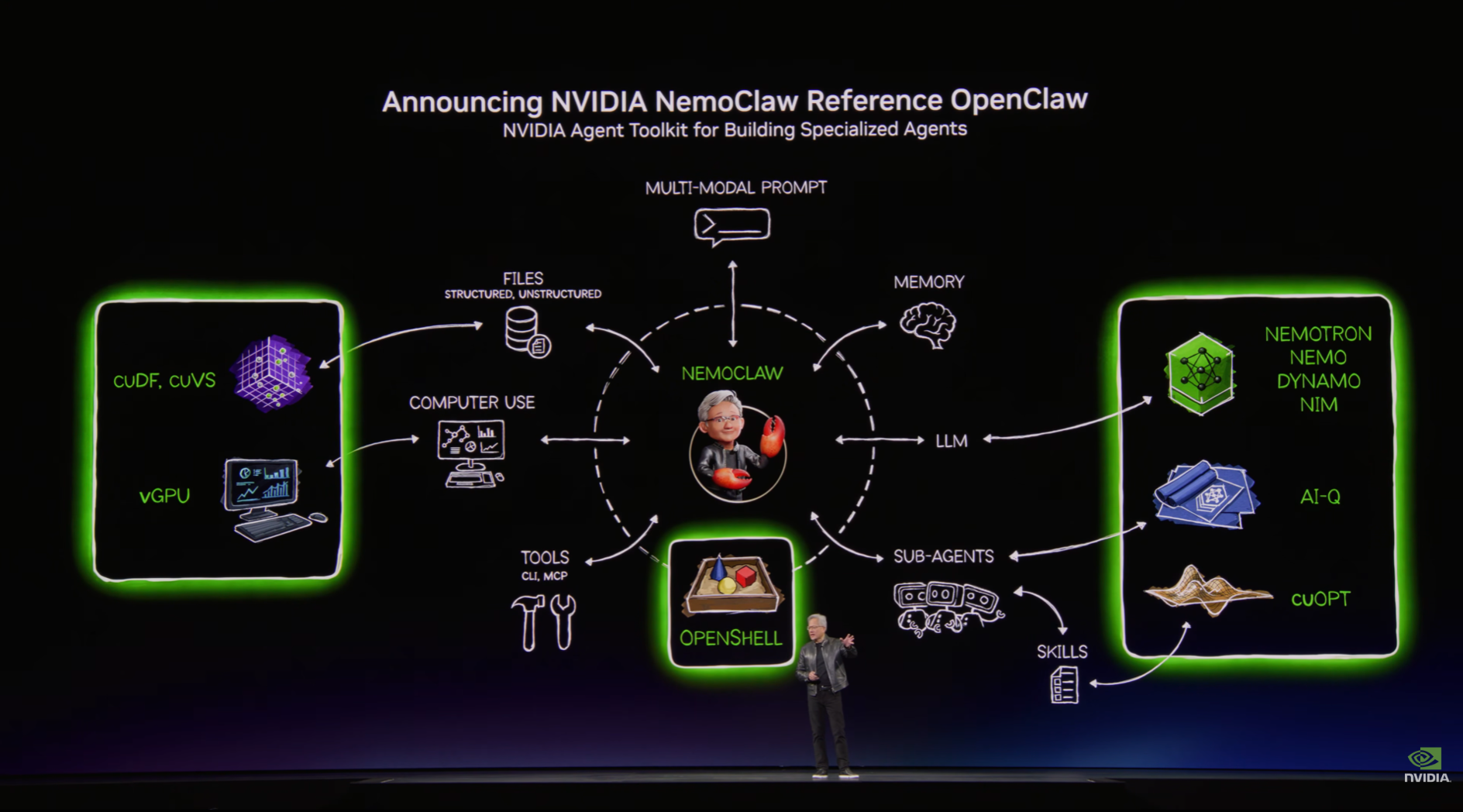
At this year's GTC, NVIDIA released its entire stack for building, deploying, and governing agents all at once. NemoClaw adopts OpenClaw as a reference implementation and applies enterprise-grade security and guardrails, while Nemotron 3 Ultra serves as the base model running on top. It is a structure that unifies creation, execution, and management into a single pipeline.
OpenAI, Meta, and now NVIDIA. The direction of big tech toward AI agents is converging. In an era where agents work alongside humans like colleagues, the ability to manage agents — a capability that might be called AR (Agent Relations), much as HR manages people — is poised to become increasingly important.
Among the four days of keynotes, one moment drew the loudest cheers while carrying the deepest implications. It was the moment Disney's Olaf walked onto the stage. Waddling on short legs toward Jensen Huang, the robot evoked the beloved character from the films. What was truly remarkable, though, was how this Olaf learned to walk.
Simulation Replacing Real-World Data
Olaf was never trained in the real world. Running thousands of virtual environments simultaneously inside the GPU-based physics simulator Kamino, it learned everything from balancing on a rocking boat to navigating around obstacles — all within hours. Instead of collecting real-world data, this approach mass-produces synthetic data through simulation and pushes past bottlenecks with raw compute power.
Jensen Huang went so far as to call this the "GPT Moment for robotics." In autonomous driving, BYD, Hyundai, and Nissan have newly joined the ecosystem, and a robotaxi partnership with Uber was announced. In humanoid robotics, GR00T N2 doubled its task success rate compared with the previous model, and Boston Dynamics, Figure, and 1X are developing on this platform.

The underlying technology stack has also come into sharper focus: Cosmos (a world model for robots to understand the real world), Isaac Lab (for building simulation environments), and Newton (an open-source physics engine co-developed with Google DeepMind and Disney Research). The core strategy is clear: bypass the bottleneck of real-world data collection through simulation, and convert the data problem in robot training into a computing problem.
Has the GPT Moment Truly Arrived?
It is worth noting that what the keynote revealed remained at the level of model architectures and training methodologies. The more critical questions to ask are: "How fast does this model respond on real roads?" and "Is latency rigorously controlled?" Since autonomous driving and robotics are domains where even a 0.1-second delay in judgment can lead directly to a fatal accident, real-world validation must be held to an even higher standard.
The reason ChatGPT was able to shift the paradigm was that anyone could try it immediately, and it delivered results that felt like conversing with an actual person. For physical AI to reach a comparable level, the entire process — from perceiving the world to making judgments and executing actions — must be implemented in near real-time within real environments. It is therefore still premature to say that physical AI has reached a true "GPT Moment."
Agents consuming tokens at massive scale and AI stepping into the physical world: these were foreseeable scenarios in the technology industry. The real challenge is the infrastructure required to support them. The layers that need optimization keep growing, and the requirements for each layer are becoming increasingly divergent. This is the backdrop against which NVIDIA declared itself not a GPU company, but a full-stack AI company at GTC 2026.
Vera Rubin: From Chips to Models
Jensen Huang compared AI infrastructure to a five-layer cake: energy, chips, infrastructure, models, and applications. NVIDIA now holds all five layers. From the GPU architecture at the bottom that governs power efficiency, through the software stack that manages the inference pipeline, to the in-house models (Nemotron) and the agent framework (NemoClaw) running on top, one company has vertically integrated the entire stack from chips to applications.
The Vera Rubin platform is the hardware embodiment of this vision — a full-stack architecture combining Vera CPUs and Rubin GPUs, concentrating 3.6 exaFLOPS of compute into a single rack. With the addition of technology from Groq (acquired for approximately $20 billion), the inference process is physically disaggregated into prefill and decode stages. Compute-intensive prompt processing is handled by GPUs, while token-by-token decode is offloaded to dedicated LPUs. This demonstrates at the architectural level that inference can be decomposed and optimized stage by stage, rather than treated as a monolithic operation.

What makes this interesting is that the vertical integration is not closed. NVIDIA unveiled six model families spanning language, vision, robotics, autonomous driving, life sciences, and graphics. The models are open for anyone to use, but the hardware and inference infrastructure on which they run best remains firmly in NVIDIA's hands. In Jensen Huang's own words, the strategy is "vertically integrated, horizontally open."
The Reality Beyond a Controlled Stack
NVIDIA already occupies a commanding position in vertical optimization between its own chips and software stack. CUDA, TensorRT, and NIM are all designed in lockstep with the GPU architecture. However, this optimization is completed entirely within NVIDIA's own stack. It does not extend beyond controlled data centers to account for the varying constraints of fragmented edge devices in the field, each with its own power, memory, and latency requirements.
Mobile, automotive, robotics, and IoT: for these markets to open up, optimization tailored to the device constraints and usage patterns of each deployment environment must come first. Ultimately, the last remaining challenge in the AI ecosystem is achieving complete codesign that encompasses not only the controlled stack but also the complex variables of real-world deployment.
Massive infrastructure like NVIDIA's Vera Rubin provides an excellent foundation, but attention is already shifting beyond servers toward edge deployment. The settings where AI must actually run — automotive ECUs, factory camera sensors, robots — are severely constrained in power, memory, and space.
Nota AI is the company that has been solving this problem. Early on, Nota AI focused on model optimization and hardware-specific optimization, building NetsPresso®. The key principle is not "one-size-fits-all compression" but "constraint-aware optimization." Even for the same model, the optimization strategy changes depending on the target chip, the allowable latency, and the power budget. Nota AI's capabilities are not just theoretical — they are validated by a growing track record with global fabless companies and big tech partners:
Optimizing for the complex constraints of real-world deployment is exactly what Nota AI does best. By working closely with end-user clients that NVIDIA's own stack does not directly reach, Nota AI delivers complete optimization and firmly fills the gap between cutting-edge technology and the field where it must perform.
Token economics, agentic AI, and Physical AI. The three transitions declared at this year's GTC may appear to be separate stories, but they ultimately converge on the same question: how to run massive models in constrained environments while preserving performance.
In data centers, tokens per watt determines competitiveness. Agents repeat dozens of inference cycles per task. Robots must make decisions within 0.1 seconds. The settings and forms differ, but the essence remains the same: inference efficiency.
This is exactly the question Nota AI has been addressing. Building a world where AI works in every environment — as GTC demonstrated, that stage is growing ever wider.

🔹 Embedded World 2026, Nuremberg — Nota AI showcased NetsPresso® and NVA with live demos delivering up to 12.5× performance improvement on the Alif Ensemble E8 DevKit, alongside LLM deployment on the Qualcomm Dragonwing™ IQ-9075 EVK.
🔹 SECON 2026, Seoul — Nota AI demonstrated NVA (Nota Vision Agent) for real-world surveillance environments at Korea's leading security and safety expo.
🔹 Nota AI × SiMa.ai — Nota AI and SiMa.ai announced a strategic partnership to advance Physical AI, combining NetsPresso® with SiMa.ai's MLSoC™ to maximize inference performance at the edge.

📅 Embedded Vision Summit 2026 — May 11–13, Santa Clara · Booth #408Come see what we've been building.