🔹 ERGO at ICLR 2026 — Efficient High-Resolution Visual Understanding for Vision-Language Models
🔹 Next-Frame Prediction at AAAI 2026 Workshop, Oral Presentation — Advancing Predictive Robustness for Vision-Language-Action
🔹 MoE Quantization — Scalable Deployment of 100B-Scale Mixture-of-Experts Models
Foundation Models have evolved from Large Language Models (LLMs) to Vision-Language Models (VLMs), and now toward Vision-Language-Action (VLA). As these models expand beyond text and perception into real-world interaction, they are increasingly being integrated into robotics, autonomous driving, and industrial automation—contexts where performance must be sustained under real-world operational constraints.
In such environments, computational efficiency, temporal robustness, and deployment feasibility become integral to model design rather than secondary considerations. The question is no longer only how capable foundation models are, but how reliably and efficiently they operate under practical conditions.
In this issue of Edge Insights, we introduce several recent research efforts from Nota AI that examine these evolving requirements from different technical angles. Together, they reflect ongoing work toward advancing foundation models with greater operational readiness for the Physical AI era.

The International Conference on Learning Representations (ICLR) is one of the most selective global venues in artificial intelligence research. At ICLR 2026, Nota AI’s paper, “ERGO: Efficient High-Resolution Visual Understanding for Vision-Language Models,” was accepted, recognizing its contribution to scalable visual reasoning.
High-resolution imagery is essential in industrial inspection, safety monitoring, and dense scene understanding. However, in transformer-based Vision-Language Models, increasing image resolution dramatically increases the number of visual tokens, directly leading to higher computational overhead and inference latency.
Existing approaches either process the entire image densely or rely on aggressive downsampling—creating a persistent trade-off between accuracy and efficiency.
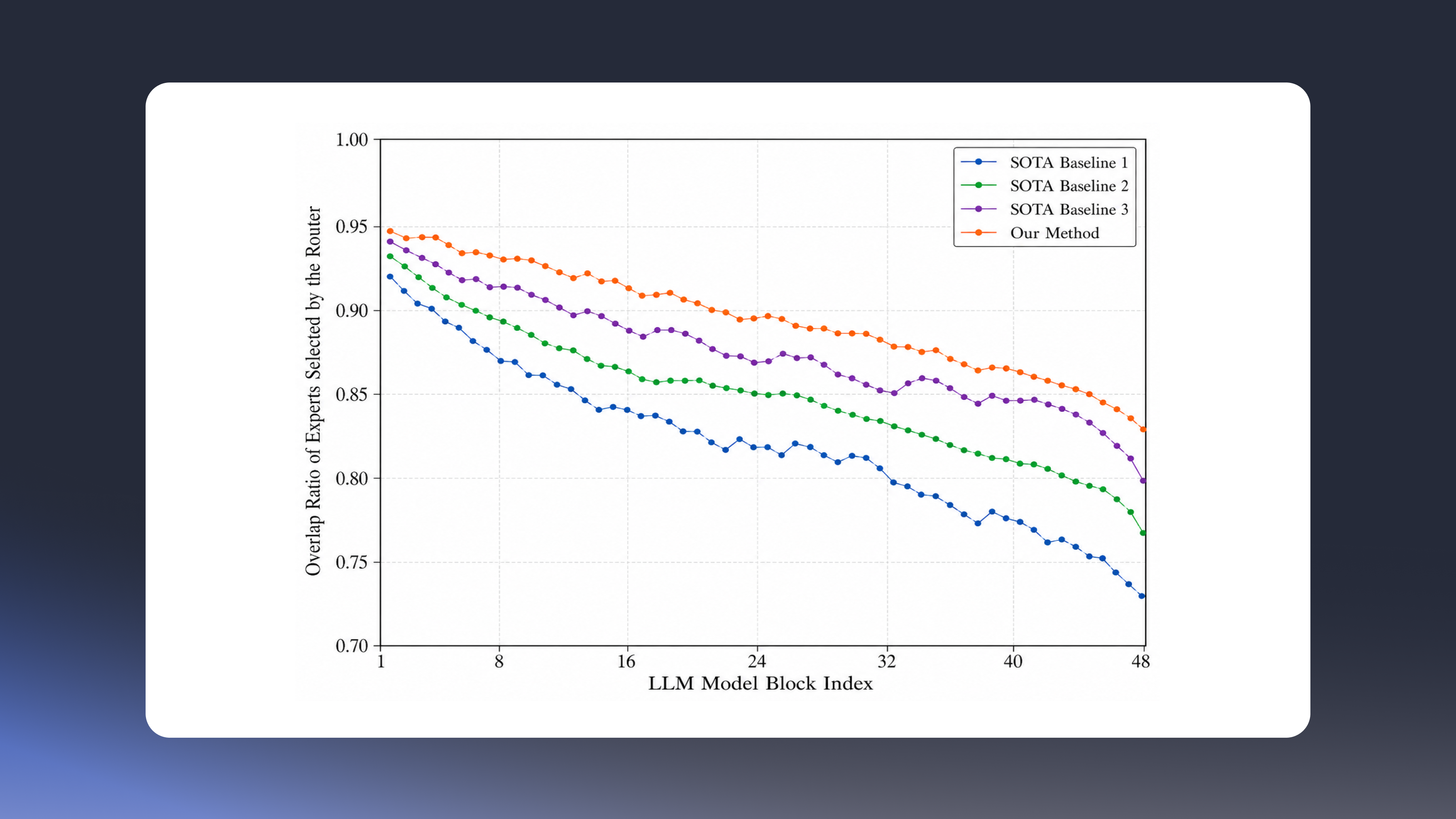
ERGO introduces a two-stage coarse-to-fine reasoning framework. A low-resolution image is first analyzed to infer task-relevant regions through contextual reasoning guided by the text query. Only those selected regions are re-encoded at full resolution for final reasoning.
Through reinforcement learning aligned with efficiency objectives, ERGO shifts from perception-driven reasoning to reasoning-driven perception—training the model to allocate visual computation strategically rather than uniformly.
Under comparable pixel constraints, ERGO achieves:
ERGO demonstrates that high-resolution understanding can be made computationally viable through structural integration of reasoning and efficiency. Rather than treating efficiency as post-processing, the work embeds computation allocation directly into the reasoning pipeline—supporting deployment in compute-sensitive industrial environments.
👉 Explore the full ERGO research in the Nota AI Tech Blog
The AAAI Conference on Artificial Intelligence is one of the longest-standing venues in AI research. At the 2026 Workshop on Foundation Models, Nota AI presented research addressing a critical limitation of static-image training.
Most VLMs are trained primarily on static image datasets. While effective for recognition tasks, this paradigm does not encode temporal dynamics. In robotics, autonomous driving, and industrial automation, environments evolve continuously. Reliability depends not only on recognizing what is visible, but on anticipating how situations may unfold.
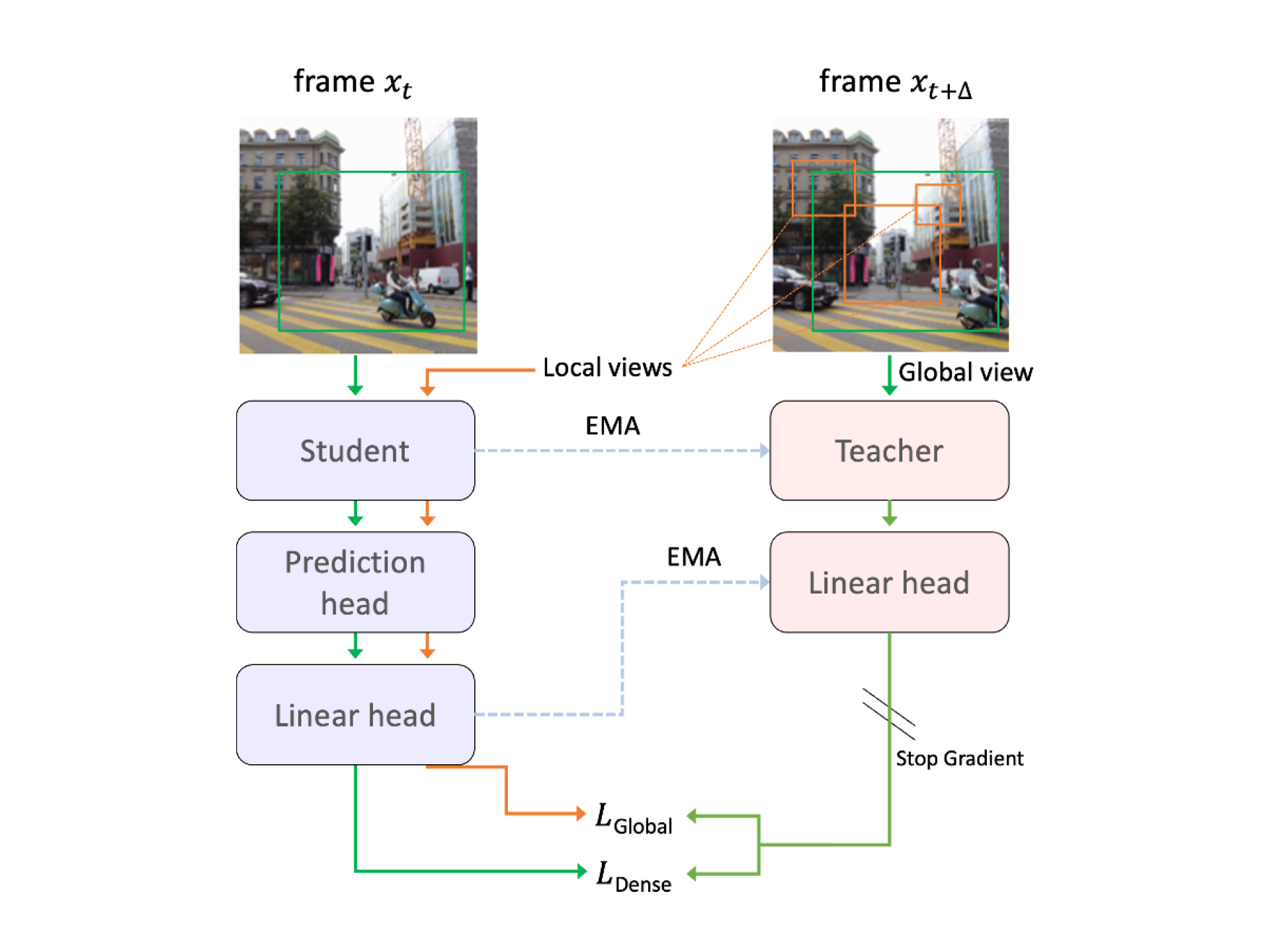
Nota AI introduced a reliability-aware training paradigm based on next-frame prediction. By sequentially injecting temporal knowledge into a single image encoder, the model learns motion dynamics through video-based training—requiring only two hours of video data.
Importantly:
Predictive robustness is achieved through training design rather than runtime complexity. The approach achieves SOTA (state-of-the-art) performance on key downstream tasks relevant to real-world deployment, strengthening robustness in dynamic environments.
This work advances foundation encoders toward VLA intelligence by embedding predictive temporal awareness directly into the model. It improves reliability without increasing inference complexity, supporting scalable deployment in dynamic physical systems.
👉 Read the full paper from the AAAI 2026 Workshop, Oral Presentation
As LLMs continue to grow in size to achieve higher performance, increasing model scale inevitably raises cost and infrastructure requirements. Mixture-of-Experts (MoE) architectures have emerged as an alternative scaling strategy by activating only selected experts during inference. However, conventional quantization methods do not account for MoE-specific routing dynamics.
In MoE models, expert selection can change after quantization, leading to representation distortion and degraded performance. At 100B-parameter scale, memory footprint and GPU requirements remain major constraints for practical deployment.
Nota AI’s MoE optimization was developed in the context of Korea’s national Independent AI Foundation Model Project, where Upstage’s Solar-Open-100B required scalable and efficient deployment.
Nota AI applied MoE Quantization, an architecture-aware quantization methodology specifically designed for MoE structures.
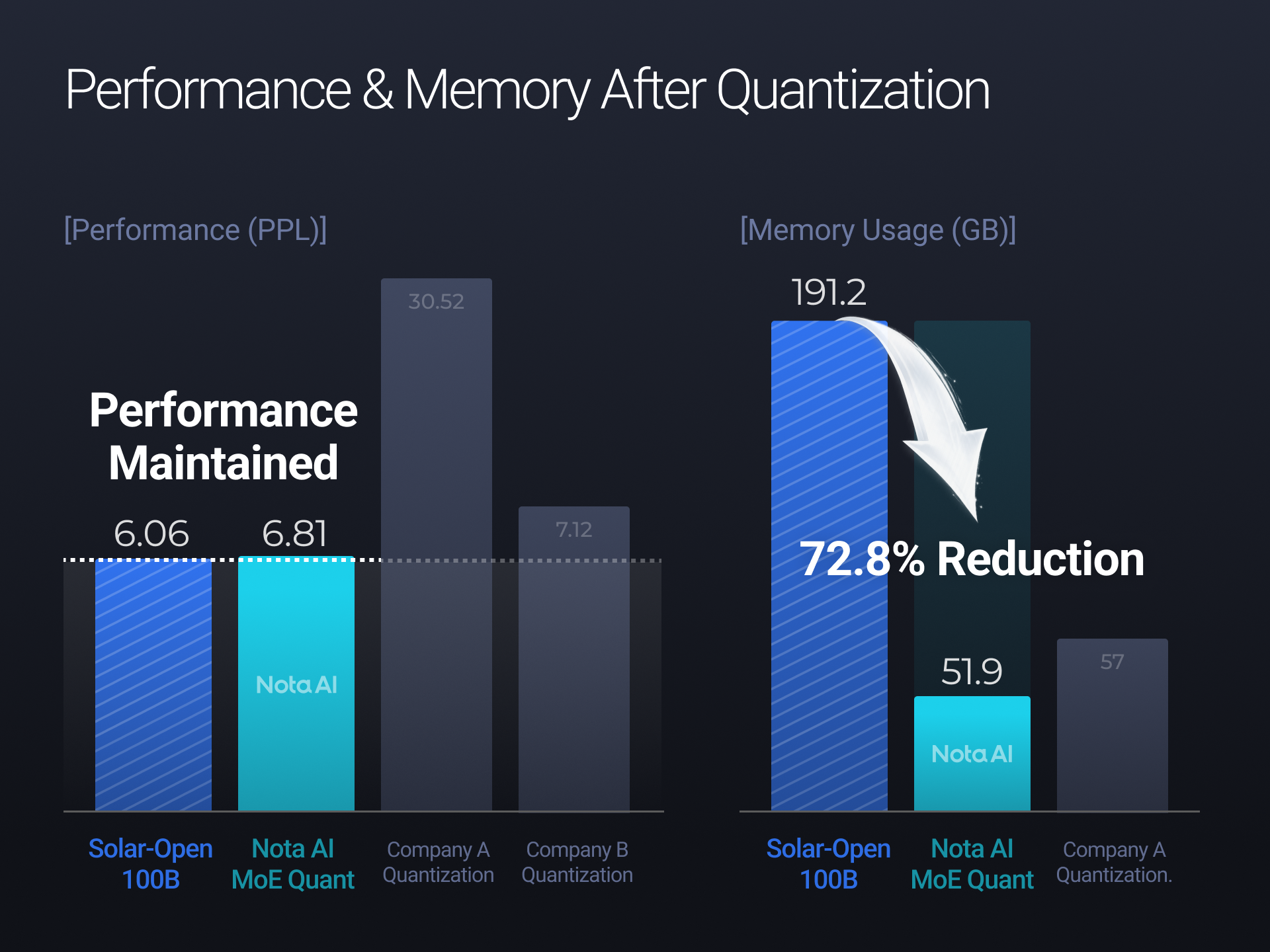
Unlike uniform compression strategies, Nota AI’s MoE Quantization preserves routing-sensitive components while selectively compressing less critical regions. It directly addresses representation distortion caused by expert-selection shifts after quantization.
The approach improves upon prior methods such as AutoRound by incorporating MoE structural considerations and can be extended to other learning-based quantization frameworks.
Applied to Solar-Open-100B:
NotaMoEQuant-INT4 demonstrates that scaling performance does not require proportional scaling of hardware resources. By structurally addressing MoE-specific distortions, the work establishes a pathway toward deployment-ready ultra-large language models with reduced inference cost and improved infrastructure efficiency.
👉 Learn more about Nota AI’s MoE Quantization and Solar-Open optimization
By aligning model capability with structural efficiency and system-level considerations, Nota AI is contributing to a more deployment-ready foundation for Physical AI.
👉 Discover more insights from Nota AI researchers on the Nota AI Tech Blog