Companies across industries are racing to integrate generative AI into their products. The global shift toward on-device AI is accelerating fast, with the market valued at 5.1 billion dollar in 2024 and projected to reach 30.9 billion dollar by 2033, growing at a 24.5% CAGR (Source: Verified Market Research).
But as demand accelerates, so does the reality check. Many enterprises soon discover that running advanced LLMs (Large Language Models) and VLMs (Vision Language Models) on existing hardware comes at a steep cost—sluggish performance, high power consumption, and escalating operational expenses. The result is a paradox: AI has never been more capable, yet never more constrained by the limits of its hardware.
This imbalance between model growth and hardware advancement has become one of the biggest barriers to the practical deployment of AI.
AI model optimization addresses this challenge head-on. By reducing computational demand and memory usage while maintaining model accuracy, optimization allows LLMs and VLMs to operate efficiently across diverse hardware environments—from high-performance cloud systems to compact, power-limited devices.
For enterprises, this means advanced generative AI can be deployed without costly infrastructure replacements. The benefits extend beyond cost: optimized models deliver faster inference, lower energy consumption, and more stable performance—making AI integration both scalable and sustainable.

At Nota AI, we’ve built deep expertise in optimizing and deploying AI models across real-world environments. Our LLM Optimization Service enables companies to bring large-scale language and vision-language models into production—whether in the cloud or on-device—without compromising accuracy or performance.
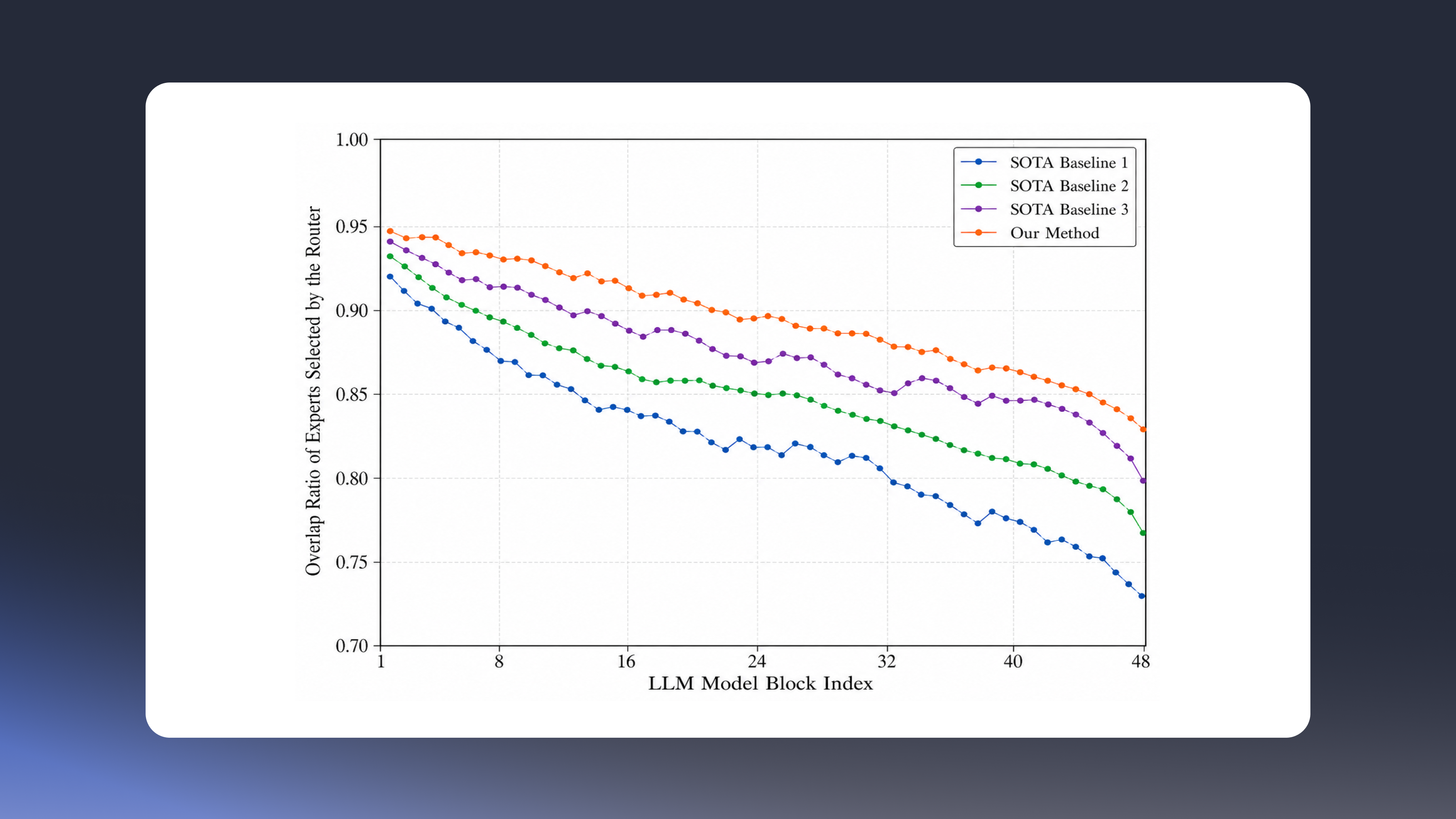
By combining advanced quantization with hardware-aware optimization, our NetsPresso® team has achieved measurable performance gains in real-world deployments. Benchmark results show that optimized models reduced memory usage by 6.9%, increased inference speed by up to 1.27×, and improved text generation quality by more than 11%—all while maintaining model integrity and operational stability.
These results prove that efficiency and performance are not trade-offs, but mutually reinforcing goals. Through device-specific optimization, we fine-tune the model to align with each chipset’s constraints, ensuring cross-hardware compatibility, lower power consumption, and consistent inference stability.
As a result, enterprises can deploy advanced generative AI models using their existing hardware infrastructure—avoiding costly replacements while achieving faster, more efficient, and more reliable performance. Applicable across consumer electronics, mobility, industrial IoT, and server our optimization service bridges the gap between cutting-edge AI capabilities and large-scale, real-world implementation.
Experience how efficient AI can power real products—without replacing your infrastructure. 👉 Learn more